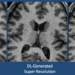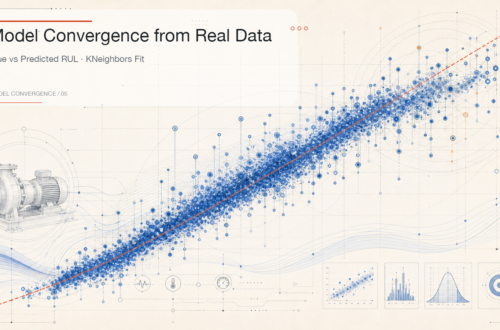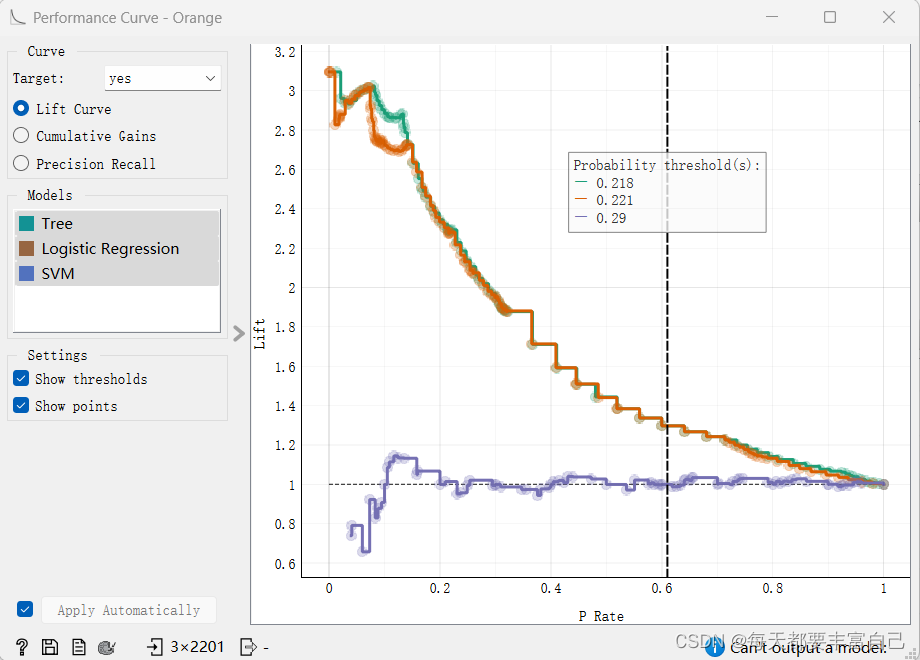


Not every studio project is a full product launch. Some are quieter investigations where we benchmark algorithms, explore datasets, and map feasibility before we commit hardware engineers or field teams. Our ongoing machine-learning research diary captures those explorations.
What we built
- Benchmark harnesses. We codified repeatable pipelines so classical models and deep nets can be evaluated across shared datasets without spreadsheet chaos.
- Insight briefs. Each study ends with a one-pager summarizing what held up, what fizzled out, and what deserves another week of prototyping.
Why it was hard
Exploration work rarely comes with perfect KPIs. We needed to protect tinkering time while still reporting meaningful progress, so we automated as much data cleaning and visualization as possible.
Where it lands
- Future roadmaps. Insights from these studies decide whether we greenlight the next edge AI sprint or shelve it for later.
- Client education. When customers ask “Can ML do X?”, we already have grounded answers, example notebooks, and constraints spelled out.
What’s next
We are connecting the research repo to our blog so these internal notes can evolve into public explainers once the NDAs lift.
Visited 21 times, 1 visit(s) today