When we kicked off the “Vibration Analysis for Remaining Useful Life (RUL) Prediction” project, the goal sounded simple: let vibration traces tell us how much runway a pump still has before it fails. In practice it meant weaving together messy CSVs, a flurry of feature ideas, and every model in our toolbox—from trusty regressors to experimental transformers. This post is the story behind that journey.
Why Vibration, Why Now?
Semiconductor fabs and chemical plants live or die by uptime. Our starting dataset—ALACB04_PTM.csv tucked under data/1000down/—captures months of pump telemetry just before failure. Instead of waiting for catastrophic shutdowns, we wanted to translate subtle shifts in DryPump current, Booster power, inverter speeds, and exhaust pressure into an early warning system. RUL regression was the natural fit: predict the hours remaining rather than a binary “healthy/faulty” flag.

Building a Trustworthy Pipeline
We anchored everything in main.py, which orchestrates the workflow end-to-end. The pipeline scans data/**/*.csv, logs every step with loguru, and writes artifacts to output/ so experiments remain reproducible.
- Data Loading & Cleaning –
DataLoaderensures schema consistency, whileDataPreprocessortrims the columns to the most informative channels and handles gaps with forward-fill to preserve physical continuity. We also generate a linear RUL label that counts down to zero at failure, making windowed regression straightforward. - Windowed Feature Engineering – With vibration data, context matters more than individual points. Our
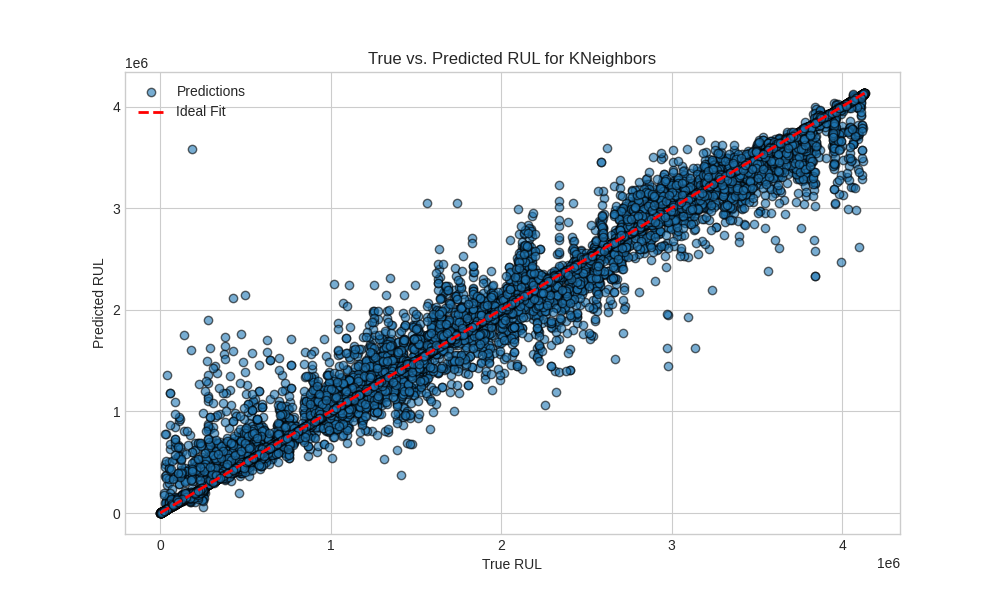
FeatureExtractorslides a 10-minute window (window_size = 600) every 60 seconds, summarizing each slice with rich statistics: RMS, skew, kurtosis, interquartile ranges, slopes, and FFT descriptors like dominant frequency and spectral centroid. The extractor even caches results incache/and can transparently switch between CPU, CuPy, or Taichi backends—handy when you jump from a laptop to a GPU node. - Model Zoo & Evaluation – After scaling features, we unleash a curated mix of regressors (Linear, RandomForest, GradientBoosting, AdaBoost, BayesianRidge, XGBoost, KNN, and friends). Sequence models (CNN, RNN, Transformer) are wired up too, behind a toggle, so we can compare handcrafted features against raw window learning. Metrics run through
ModelEvaluator, keeping MAE, RMSE, and R² side-by-side in the logs, while best-performing weights get serialized viajoblibinoutput/models/.
What We Learned
- Quality beats quantity. The biggest gains came from disciplined preprocessing: forward-filling aligned signals better than aggressive interpolation, and dropping non-numeric columns early prevented spurious FFT artifacts.
- Windows capture reality. Pumps don’t fail in single spikes. By overlapping windows we captured gradual drifts—increasing RMS on
DPTemperatureor widening IQR onExhaustPressure—that single-point models would miss. - Classical ML still shines. Despite experimenting with CNNs and Transformers, a well-tuned RandomForest plus engineered features offered competitive accuracy with far less training fuss. Deep models remain promising for multi-sensor fusion, but they demand more labeled runs than we currently have.
- Caching saves sanity. Feature extraction is the slowest step; persisting
{features, targets}with a cache version token meant we could tweak models repeatedly without reprocessing gigabytes of vibration data.
How to Reproduce It
- Create a clean environment:
python3 -m venv .venv && source .venv/bin/activate. - Install dependencies:
pip install -r requirements.txt. - Drop new CSVs under
data/<batch>/(never overwrite originals). - Run
python main.pyfor a full sweep, orpython analyze_csv.py --path data/1000down/ALACB04_PTM.csvto sanity-check a single file. - Inspect
output/results/for metrics andlogs/pipeline_*.logfor a narrated run.
What’s Next
We’re lining up additional datasets to diversify operating conditions, experimenting with attention-based feature masks, and drafting pytest suites under tests/ to guard the preprocessing math. On the ops side, we’re planning a lightweight predict.py CLI that loads the latest model and emits RUL for freshly streamed sensor blocks—making it easier to embed in maintenance dashboards.
If you’re working on similar predictive-maintenance problems, we’d love to compare notes. Drop a comment or reach out—there’s plenty more to explore in the vibration universe, and the pumps aren’t going to wait for us to finish tinkering!